LONG READ
What will it take to stay one step ahead of a mutating COVID-19?
As new variants of COVID-19 rage around the world, we examine how scientists are fighting to be able to anticipate them – and how this will translate into government policy at home.
Published On 22 Feb 2021
As of now, nearly 110 million people around the world are known to have been infected with SARS-CoV2, the virus that causes COVID-19 and which first came to light more than a year ago. The actual number of people who have had the virus is probably higher as many cases are asymptomatic, and others went untested during the crisis. In 2021, new variants of the virus have led countries to shut borders, cities to reimpose lockdowns and health ministries to declare second, third and fourth waves.
It might seem that by now, after thousands of scientific papers, that the global scientific community would have new tools to anticipate new variants, and the wisdom to stay a few steps ahead of new outbreaks. But identifying and catching dangerous variants of a novel disease early remains maddeningly difficult.
Keep reading
list of 4 itemsUS top doctor says vaccination key to fighting COVID-19 variants
Kent COVID variant: What you should know, in less than 500 words
Brazil says Amazon COVID-19 variant three times more contagious
With the pandemic coursing into its second terrible year, it is worth revisiting some fundamental questions. How do scientists see what is happening to the pathogen? How do they know their findings are accurate? How do they translate what they find into recommendations for policymakers? And how do they see what might come next: in this epidemic, or the next one?

Keeping up with mutations
Compared with other single-stranded (RNA) viruses like influenza, polio or dengue, the coronavirus family has the longest genome – the chain of molecules which make up the “code” which builds the virus. The SARS-CoV2 genome is about 30,000 letters long, nearly double the length of the nearest distinct virus order. This complexity may allow coronaviruses to jump more easily between hosts and species, but it also means that their own self-replication process is prone to making errors which can result in mutations. While mutations can help the virus adapt to new hosts, too many mutations and the virus could quickly extinguish itself, having changed beyond survivability. To counter this, they are the only viruses of their kind which have a built-in proofreading tool – a little enzyme which checks for errors during the copying process and discards bad copies.
SARS-CoV2 is sloppy inside human cells, however. As the virus copies itself using human machinery, it snips and tosses away shreds of its own genome, recombines with bits of others floating around the same cell, and even carries discarded shreds of genome pieces to the next host cell like an ill-mannered and uninvited hoarder. The transiting virus “looks like a garbage bag,” says Mark Denison of the Vanderbilt University Medical Center, who has studied coronaviruses for decades. Out of this genetic mess, new strains of virus with new traits occasionally emerge to compete for dominance.
Globally, the SARS-CoV2 virus is infecting trillions upon trillions of cells all the time and yet, according to one estimate, it only accumulates a few stable and novel variants every month (one prominent research group says the virus accumulates one or two mutations per month, while the World Health Organization (WHO) says it cannot make an accurate estimate yet). Most variants are mundane; swapping one building block for another, but some are more effective at spreading the disease. The more pools the virus splashes around in, the more varieties will splash back out.
“If you think from the virus’s perspective of 100 million people, billions of cells, the virus is replicating 24 hours a day, seven days a week, leaving one cell and moving to another – the numbers game for the virus becomes trivial. The opportunities are astronomical,” Denison says. “When we get to a billion of anything, anything can happen.”
One of his labs – in a project led by a graduate student named Jennifer Gribble – recently removed the proofreader enzyme to test how the virus fared. Without it, SARS-CoV2 rapidly declined. The proofreader enzyme is one potential target for antiviral therapies, like Remdesivir, an expensive antiviral which has been found to be effective against the virus but only if administered before the body’s immune response goes into overdrive. It is mostly only available in rich countries.
New models, as fast as you can build them
When a variant competes for dominance and wins, it may change the dynamic of an outbreak, but it will not ring alarm bells immediately. The first significant documented change to SARS-CoV2 was a modification in its spike protein in early 2020 called D614G, which rapidly dominated the globe. D614G likely emerged last year in January, in China and Germany, and in Italy in February. It seemed to cause people to have a higher viral load – more of the virus duplicating inside their cells – but did not seem to cause worse symptoms or a higher death rate. Doctors were talking about it on Twitter in the spring, and a major scientific paper about it was published in June.
Carl Pearson is a research fellow who builds mathematical disease models at the London School of Hygiene & Tropical Medicine. Sarah Cobey is a PhD epidemiologist and evolutionary biologist at the University of Chicago. She watches the numbers, builds models and advises state policymakers on the latest data.
For these two scientists on opposite sides of an ocean, the charts that show how COVID-19 is moving through a population are narrow windows into deep datasets, and they are almost always incomplete.
“Most folks have some experience with taking a physics class,” Pearson says from London. “There are equations: you throw the ball, it will go in a parabola. If you throw it this fast, it will go this high.” In epidemiology, however, “this notion of physics-based models, I think, is detrimental to expectations”.
Epidemiologists look at the humans who host the pathogen. There are susceptible people, infectious people and “removed” people, and there are various estimated transmission rates. For SARS-CoV2, there is an extra kink: asymptomatic spreaders, who might not be recorded.
An initial model may show a period of exponential growth, plateau and descent – a wave – Pearson explains, but “people aren’t billiard balls”. The effects of new conditions like stay-at-home orders, closing certain types of businesses or imposing masks can be estimated. “Turning [a factor] off in the computer or on paper is distinct from what actually happens in the real world.”
Spotting new variants – a game of catch-up
The really vexing problem – and the issue still successfully evading scientists – is how to pinpoint when the virus transmits between people. So, scientists cannot measure the moment that you pass the virus to me, and I pass it on to three other people. They can only estimate by looking backwards.
In Chicago, Cobey is building models using three of the current most reliable data points: hospitalisations, deaths from COVID and deaths that are presumed to be from COVID but are not confirmed. These are combined with known lag times between the moment of infection and the disease’s worst manifestations.
“What we’re not doing now is looking at how many people are going to the grocery store, or on public transport,” Cobey says – ie, epidemiologists still only look at data related to testing, hospitalisation and deaths; they are not measuring how we move around the world and might be infecting each other. “Instead, we have to take a much coarser approach. The global community does not yet have good information about fine-scale risk like that.”
Carl Pearson’s models monitor the outbreak in African lower and middle-income countries. His team deploys supercomputers to estimate outcomes based on various possible rates of transmission. Pearson says the most effective approach is to decide what questions should be asked of the models before they are built.
Models are being built all the time and can be tweaked. A model can be drawn up, for instance, to describe a local health clinic’s expected patient load, or a city’s expected COVID infections in two weeks’ time if rules about wearing masks are adhered to.
Some policymakers want a disease model that shows simple answers – for instance, how to anticipate the needs of a region, how to prepare for a rise in demand for beds, ventilators or drugs. “A lot of early questions [from health ministries] were ‘Hey, tell us what to do,’” Pearson says. His team flipped the question, asking ministries instead, “What is the decision you’re trying to make?”
Cobey and Pearson know that dangerous new variants to the virus will occur but they and other epidemiologists will only spot them in the data after the situation on the ground falls out of sync with what was expected by the models. “When the patterns are broken, we investigate,” Pearson explains.

In the Eastern Cape, after the winter holidays, hospitals became overwhelmed with more patients than the models had anticipated. Something about the virus had changed. But what? And where? Urgent phone calls linked institutions and the WHO got involved. Pearson’s team produced a model in January that looked back at the alarming speed of the new South African outbreak. It looked like a variant, a slightly more infectious version of the original virus.
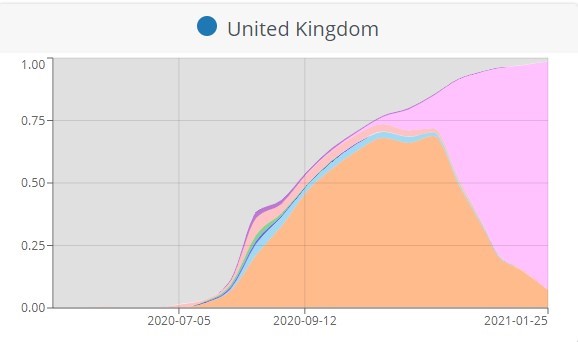
In the United Kingdom, a coincidence gave away the new UK variant’s location. The standard test used for detecting COVID-19 identifies a handful of the virus’s genes. The new variant, which happened to spread more aggressively, had changed the virus’s genome just enough that some of these targets did not light up. Looking back through the testing data it was obvious where the strain was spreading. “Humans were watching and saw an interesting pattern and said something is going on here, [and] the target failure happened to correspond with that error,” Pearson says.
National borders slammed shut like metal storefront curtains in a riot, but both of these variants had already burrowed abroad.
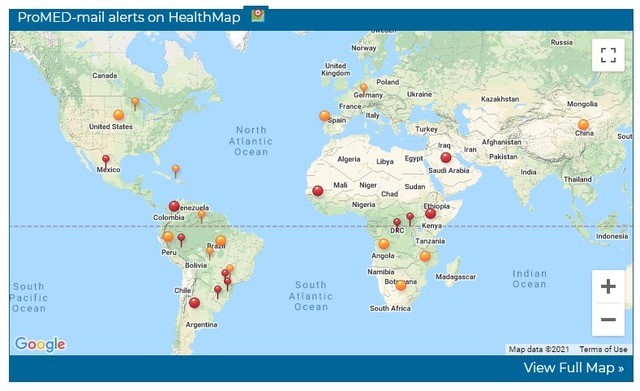
Disease trackers, therefore, look backwards, connecting today’s data to piece together yesterday’s outbreak and predict tomorrow’s possible outcomes. Could we capture more data to help with this?
Big tech firms – Facebook, Apple and Google included – have published anonymised users’ movement data sourced from smartphones.
Harvard epidemiologist Caroline Buckee studies these new data sources, mostly coming from advertising technology firms, also known as “ad-tech”. Recently, she addressed a webinar hosted by Emory University. “For the first time, we’re able to get real indicators of human behaviour and see the behaviour that might lead to transmission,” she explained in her presentation. Some of it is “incredibly useful”, she said, while some of it is incomplete.
Data sources from ad-tech “are variable in terms of how open they are”, she explained. “[Companies] develop their own metrics; we often don’t know how many people are in a data set, and for almost all of them, we don’t know how representative [the data] is.” Smartphone users, for example, are a subset of the population and tend to be young and wealthy. People who do not own smartphones, or who own them but do not carry particular apps, for example, simply will not exist within these datasets. This may include wide groups of people of a particular ethnic background or age.
We should study this data, she said, but we have yet to determine how to use much of it quantitatively or uncritically.
Pearson seems to agree. He is also experimenting with some of these new toolsets. He says that traditional epidemiological tools – measuring “how many cases, among whom, in what setting, etc” – are still better, however.
Cobey would love to receive more data. A surveillance system for capturing symptoms as they emerge in a community – so-called sentinel surveillance – would be a strong start. Antibody testing, or seroprevalence, in a truly representative population would be best. “Seroprevalence,” Cobey says, “could tell us right away the state of population immunity and help us understand the quality of past surveillance in different areas: what fraction of infections did we actually detect?” She thinks of it as a giant piece of infrastructure: “We need to be doing these studies.”

Predicting outbreaks like the weather?
In fact, there already is a familiar system that predicts a chaotic global process: weather forecasting. Could epidemic surveillance one day look like the weather, with pathogen storms on the horizon and advisories not to go out before a particular strain hits a region?
“It’s not a bad metaphor,” says Cobey, but “there are two caveats: with weather you are looking at a lot of turbulent flows – chaos – which limits predictability.”
With pathogens, the outlook is different. “I find it embarrassing that we scientists are not good at anticipating things – behavioural measures included. Maybe in a few years we’ll learn how we could do that. The area that will always be a thorn in the side will be for fast-evolving pathogens: the RNA viruses, the bacteria, where we have evolution which is quite open-ended and unpredictable, and how the immune system responds to a particular pathogen. Those will put a fundamental limit on predictability.”
Pearson bristles a bit at the comparison to weather forecasts. “I would love for us to be where the weather is, someday, but there are distinct differences [to] what we do with infectious disease modelling. You can watch a weather system in detail off the coast without violating anyone’s privacy rights. You can generate storms in the lab. We can’t infect people with a pathogen to see what happens.”
Despite this pandemic taking place at a time of unprecedented personal tracking software streaming users’ location and health statistics, he adds: “I hope we never get to the place where I have a tracker in my neck that reports my vital statistics.
“I don’t foresee some all-seeing beneficent AI that will take care of us. We will always have to have people who are actively looking at things like hospitals filling, abnormal numbers of new cases.”

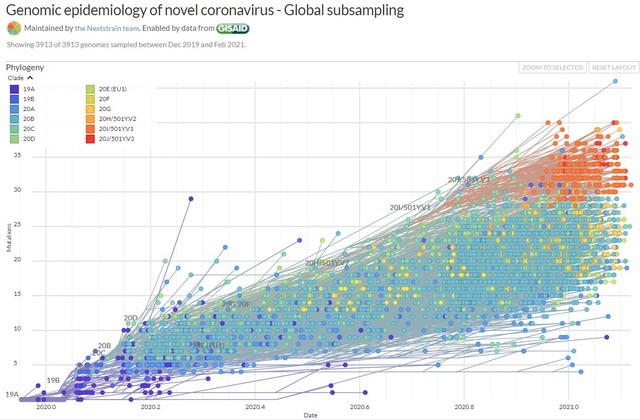
The SARS-CoV2 genome contains more than just code to build new viruses. Their RNA is a record of where they came from as well. When scientists compare one virus’s genome to another, the changes it has accumulated are like a timeline that links it to previous generations. This is called molecular clocking. When they compare thousands of virus genomes at once, the paths the virus has taken branch out like a tree – called a phylogenetic tree.
The UK leads in genomic sequencing of SARS-CoV2 samples, having captured about 10 percent of the known virus cases in the country. Germany sequences about five percent of its cases, thanks in part to a government scheme to pay for every sample, an incentive that brings private labs into the process. South Africa, Nigeria and several other African countries host genomics surveillance facilities. Recent news reports from the US have revealed that the country where many sequencing technologies were developed still has minimal coordination for viral genomic surveillance, however.
“As soon as we get samples, the process can go very fast,” says Sebastien Calvignac-Spencer of the Leendertz lab at Robert Koch Institute in Germany. “It takes one or two days before you’re able to reassemble the [virus’s] genomes.” Genomic sequencing in an outbreak does not have to be exhaustive either, Calvignac-Spencer says. Sampling just a fraction of the epidemic’s viral sequences would give scientists enough data to follow new variants of concern. “A few percent to 10 percent should catch most” of the emerging variations, he adds.
Sequence data are vital to understanding how an infection is changing but, in isolation, they do not reveal much about how, where and when the virus will spread in the future.
“We cannot really predict anything from the [viral] sequence itself,” Calvignac-Spencer says. “Genomic surveillance is only an interesting tool if you have independent sets of data flowing in as well.” He is referring to public health information from the front line about who has contracted the disease, when and how sick they are. “We do not have a gigantic artificial intelligence black box we throw a variant [sequence] into to identify patterns.”
Genomic surveillance – a new standard for public health
COVID-19, more than any previous outbreak, has made genomic analysis a standard tool for monitoring an outbreak. “Even in science, genomic surveillance was thought of as a research tool, not a public health tool,” Calvignac-Spencer says. “In Germany, we see the change in the mindset of our leaders. Now they see the value of implementing wide genomic surveillance.” Overall, the technology of genomic surveillance has improved a great deal, while country leaders are running scared from new variants. Both these factors have made genomic surveillance a more popular approach during the COVID pandemic.
Maria Van Kerkhove, the technical lead of the WHO, sits at the table with Director-General Tedros Adhanom Ghebreyesus every week to present the world health body’s latest findings in relation to worldwide health generally and COVID-19 specifically. She lists the dozens of teams, working groups and agenda items she oversees as if she were orchestrating a very large family reunion.
The WHO estimates that 350,000 SARS-CoV2 genome sequences have been publicly shared. These are archived between a dozen independent institutions around the world. Most of these sequences come from just a handful of wealthy countries, so they are working to increase capacity in the developing world now. Van Kerkhove says the WHO is focused on coordinating diverse data streams, ensuring scientists have access to all of the data and building sequencing capacity where it isn’t yet.
“Some of the tech is the size of a chocolate bar,” she explains, referring to some of the latest genetic sequencing hardware. “Tech is not the problem; it’s building capacity. We have to share that sequencing to platforms for archiving, sharing and analysing.”
A recent study in the Lancet confirmed that the small West African countries, The Gambia, Equatorial Guinea and Sierra Leone, have sequenced more of the viruses in their populations than France, Italy and the United States. This information will help authorities there control outbreaks. These countries, of course, have vastly smaller populations, but it is an indication of how some sequencing capacity, well-deployed – can go a very long way.
In June, the WHO established a risk-monitoring framework in the form of working groups that meet regularly, specifically to look for new variants of SARS-CoV2. This is built on surveillance systems that were already tracking flu, HIV, polio and TB.
“Right now, we are reactive; we detect mutations,” Van Kerkhove says. “Now we’re seeing variants. They’re not unexpected. You have so many mutations in a virus, and a lot of that is because of the pressure the virus is under after a year of circulation and 100 million cases.” Van Kerkhove’s teams update governments every week, and when new hotspots emerge, they speak to health ministries daily.
Is there one single data stream yet, a firehouse of SARS-CoV2 science and sequences? “No, there is not,” she says, “but there doesn’t have to be. What we need are those portals linked.”
The ‘language’ of infection
Calvignac-Spencer doesn’t have a black box to predict dangerous variants, but Bonnie Berger’s lab at the Massachusetts Institute of Technology is trying to build one. The twist is that their tool was designed to learn the rhythms of human languages, not biology.
The SARS-CoV2 virus’s proteins are built with amino acids. Like Lego bricks or Tetris tetrominoes, they stack up in predictable alignments, similar to words in speech. Words “fit” near other words predictably, and software has become extremely adept at learning these patterns. Berger and her researchers, therefore, have created a grammar and syntax for viral protein assembly.
In an example taken from their research, the sentence, “blast off of Apollo 8”, makes sense. Replace a word: “Blast off of Apollo 13”, and it means (roughly) the same thing. “Blast victims of Apollo 13” makes grammatical sense, but means something else entirely. The new phrase might slip past a filter that was screening for small variations.
To predict variants in the virus, Berger’s team substitutes virus blueprints for words. She’s looking for variants that are fit enough to continue infecting, but transformed enough to evade the immune system’s antibodies. This combination is called “immune escape”, and it is the thing that keeps infectious disease experts awake at night. Theoretically, it may be possible to predict what a new variant in the future will look like – but it is not something scientists can do yet.

Berger’s team fed their tool thousands of known virus genetic sequences for flu, HIV and SARS-CoV2. They looked through the results and compared the findings with known “immune escape” examples (variants that are different enough to evade immunity, or possibly even a vaccine) in lab data. The matches were mostly accurate, showing that the system works pretty well even if it is not perfect.
“Right now, the escape mutants highlighted by our model could already inform laboratory testing, to narrow down the universe of mutations that could conceivably preserve fitness and even lead to escape (ie, be less responsive to a vaccine).”
This model could in future lead scientists towards two useful goals: predicting the next dangerous variant, and targeting drugs to the parts of the virus that are least likely to change over time.
The results were published in the publication, Science. The tool is not ready to deploy but theoretically, it could spot variants faster than lab experiments that require time and labour to culture virus samples in tissue.
“In the next couple years or so, these techniques could become commonplace for monitoring [pathogen] evolution,” Berger says. “[But] before making epidemiological decisions, we really want a better idea of “calibrating” a change threshold where, if our model predicts a semantic change above a certain level, then we would send a red flag to different policymakers (for example, the Centers for Disease Control). Once we do that, our system could operate near instantaneously.”
Difficult decisions
Models, sequences, predictions. How do governments make sense of these incoming data streams, and make decisions that can carry real economic and human costs?
“We have to be careful, we have to be sceptical, and we have to be data driven”.
Isaac Bogoch is a general doctor and a member of the vaccine task force in Toronto, Canada. Above all, he says, communication is paramount. “We need to be honest and transparent about what we know and don’t know. We have to know how to communicate what we don’t know, [because] people can’t stand uncertainty.”
It is especially hard to advise populations to worry about a variant if they are already taking precautions, however, because the advice is the same. “What are you going to do,” Bogoch asks, “wash your hands harder? We continue to adhere to putting on a mask, better ventilated spaces, avoiding close, crowded, confined spaces.”
Calvignac-Spencer says that new innovations and data streams are welcome, but humans will always be the front line against infectious diseases. As governments gain more control over new outbreaks in the longer term, he predicts: “We will [come] to accept that citizens are the first building block of the public health system: you eat well, you sleep well, you wear masks, you understand science.”
One US-based expert in biodefence and disease surveillance, who did not want to be named due to ongoing work for private firms, agrees. “You can do all the modelling in the world, you can have high-tech surveillance tools,” she says, “but in a new pandemic, you’re picking up signals that are novel: you don’t know what they mean. The silver bullet idea of using technology to overcome all obstacles is not the best use of people’s time. We need tried-and-true [human] tools.”
Bogoch says one new technology does give him hope. “MRNA vaccines are amazing,” he says, referring to the innovative formulae devised by Moderna and Pfizer and deployed for the first time during the COVID-19 pandemic.
The cutting-edge vaccine delivers a remarkably simple package to stimulate the body’s immune system. These are tiny strips of messenger RNA, which human cells use to print the SARS-CoV2 virus spike proteins, which are then recognised by the immune system and “remembered” for the next infection. MRNA vaccines have been shown to be remarkably effective.
“What happens if there’s a variant that evades vaccination?” he asks. Companies could recode the vaccine. “You could tweak the vaccine and mass produce it quickly. You have the tech, you have the capacity, you could roll it out.”
While the flu vaccine is tweaked every year to adjust for new flu variations, it is an intensive global process requiring consultation, incubation within millions of chicken eggs – mostly in Asia – and a complex transport chain. MRNA vaccines could be recoded and printed from the same facilities in a fraction of the time.
Watching for the next one
Bogoch was not caught off-guard by this coronavirus, not because he was watching the news, but because he received an urgent email about it on December 30, 2019. In early January, 2020, he wrote a research paper called Pneumonia of Unknown Aetiology in Wuhan, China, rating the health-preparedness of cities linked to Wuhan by air travel.
The email he received was not confidential. Bogoch knew about the outbreak because he and about 90,000 other doctors, health professionals, policy makers, biosecurity advisers and journalists follow a listserve (an email subscription service which was common in the early days of the web) that has been distributed via dozens of emails a day since 1994, called Pro-Med [Program for Monitoring Emerging Diseases], by the International Society for Infectious Diseases (ISID). Pro-Med is still run by volunteer experts from offices stacked with shelves of stuffed binders. They fill in the cracks where politicians and health ministries may be anxious to tread. For example, the Chinese authorities did not report the outbreak to the world immediately, while many other countries – some states within the US included – have been accused of misrepresenting early COVID numbers.
Marjorie Pollack is a deputy editor of Pro-Med and has been with the listserve since it was founded. A doctor of internal medicine and an alumnus of the Epidemic Intelligence Service of the US Centers for Disease Control (CDC), she is based in New York. She edited and published the alert from Wuhan within a few hours of learning about the “unknown pneumonia”. “Oh yes,” she laughs, “I was very much there.” On December 30, 2019, a medical source in Taiwan wrote to Pro-Med staff about a social media post concerning a new respiratory illness in Wuhan, China. Pro-Med staff looked for more information, and found a news story in a business publication in Wuhan that had approached the local ministry of health for comment and then run a story about a new virus. The whole process took a few hours. The next day, the Chinese government informed the WHO of the outbreak.
Pro-Med is a global network with eyes on all continents. “We have bacterial disease moderators, viral disease moderators, parasitic disease, plant disease, wildlife, epidemiology and surveillance moderators, five animal health moderators and networks across every region of the world,” says Pollack. It publishes in several languages. Each moderator is paid only a small stipend – “to cover home internet costs”. The service is free to receive, and it publishes dozens of alerts a day.
“An 80-hour week for me would be a light week,” Pollack says, not as a joke. Once just operating from email alerts and news tickers, Pro-Med now uses social media and advanced search services like Dataminr as well, but Pollack and her colleagues maintain the same strict rules. Leaks are welcome, but never from anonymous sources. Information is always double-sourced. Pro-Med never reveals a source who asks for privacy. Politics are not involved.
“Our network crosses some of the political boundaries that, for instance, WHO networks do not,” says Pollack. “It’s very simple. Pakistan is next door to India. Yes, they throw an awful lot of rhetoric at each other, but the reality is microbial organisms are not involved in those fights, and they will make their way across those borders. If you look at the [Middle East] region, you’ll see posts on Israel. The recognition is Israel is there and microbial organisms cross. It helps that there are not those political constraints.”
Alerts tick in to Pro-Med as we are talking: Avian influenza, Nigeria. Avian influenza, Bulgaria. Acidovorax citrulli blotch, tomatoes, Greece. Wild-type polio, Liberia. E coli from an unknown food source, USA. Brucellosis in caribou, USA. Emails come every hour.
“We started as an informal network. Now we use the terminology of innovative disease surveillance. One of the mantras, and this is something I feel very strongly about as a CDC-trained individual, is don’t try to formalise what’s informal. You will lose the value of informal. People trust us. We’re a known entity.”
More alerts, just a few hours later: Rabies in dogs, South Africa. Foot-and-mouth disease, Uganda. Rift Valley fever, Eastern Africa. Sea star wasting syndrome, North America.
Pro-Med is funded by a foundation which is supported by health charities and some governments. Its independence is one of its core assets. “We have occasionally p***ed off governments,” Pollack says, “but they come around. They’ve gotten angry if something was put out that was not through them.”
ISID’s small volunteer staff has had to split time to cover the rush of COVID news – including reports on new variants – while monitoring other outbreaks around the world.
“We’re still paying attention. We’re trying not to ignore what else is going on. My big concern with the social media systems is, everything is COVID. It’s hard to find not-COVID.”
More alerts, after midnight: Eastern equine encephalitis, North America. Syphilis, Japan. Monkeypox, DRC, 1,000-fold increase over 2019.
In the haze, I ask Pollack if she has ever seen or heard of anything new that has kept her up at night. Has she glimpsed the next pandemic-potential pathogen?
“No,” she assures me. “I would be screaming.”
Source: Al Jazeera